It’s Probably Only Getting More Important to Use (Good) Structured Data
Exploring the purpose of structured data in the SEO game, why it's poised to become even more important in the future, and how to start leveraging it well.
Search engines have long been scarily good at understanding content on the web, but there's still a lot to be gained by making explicitly clear what you're trying to say and whom it's intended to help. Tools for doing that have existed for decades – meta tags, sitemaps, and even your robots.txt file.
One of the more complex and less understood of these tools is structured data – the specially formatted information embedded onto a page, specifically intended for machines to read.
Until now, those machines have almost always been search engines. And they've largely just used it for generating rich snippets like these:
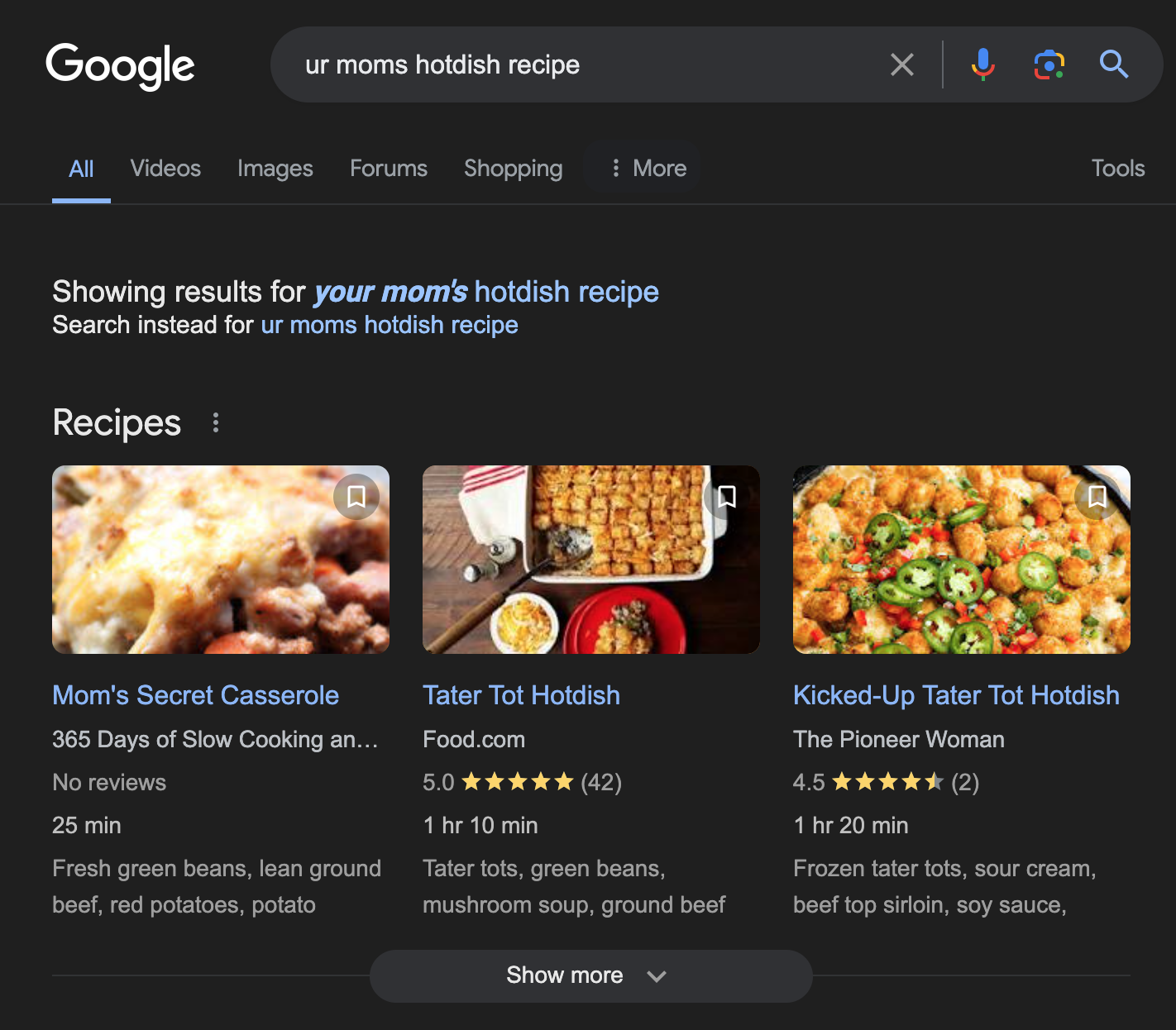
But we're in an AI/LLM world now. The traditional understanding of a "search engine" is in flux, and our content is already being read, analyzed, categorized, and regurgitated by an entire new race of machines. In that light, I'm expecting structured data to become a whole lot more important, as is your ability to leverage it.
A Very Truncated History of Structured Data
If you've worked with structured data, you're probably thinking of the JSON-LD flavor found in a <script type="application/ld+json"> tag. For a recipe, it might look like this:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Recipe",
"name": "Ur Mom's Hotdish",
"author": {
"@type": "Person",
"name": "Ur Mom"
},
"description": "A really good receipe.",
"image": "https://example.com/ur-moms-hotdish.jpg",
"recipeIngredient": [
"1 lb ground beef",
"whatever's in the fridge",
"love"
],
"recipeInstructions": [
{
"@type": "HowToStep",
"text": "Preheat oven to 350°F."
},
{
"@type": "HowToStep",
"text": "In a skillet, cook ground beef so you don't catch a parasite."
},
{
"@type": "HowToStep",
"text": "Throw everything in the oven. Play a round of Court Whist."
}
],
"recipeYield": "5 servings for each Scandinavian farmer in your family."
}
</script>But that's not the syntax we started out with. That story begins a bit earlier than you might think.
Most web page publishers only started caring about structured data when Google launched rich snippets in 2009. At the time, two formats were supported for embedding metadata into pages – microformats and RDFa. But the roots go back a decade earlier, even before all life forms were obliterated by the Y2K bug. In fact, the concept was first championed by Mr. Internet himself – Tim Berners-Lee.
Berners-Lee wrote Weaving the Web in 1999, laying out his vision for a "semantic web," a prerequisite for machines being able to read the web, form connections throughout it all, and extract meaning. Directly from that book:
A “Semantic Web,” which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy, and our daily lives will be handled by machines talking to machines.
Stepping toward that meant more than writing clean HTML. It would require a standard by which ancillary information exists in the code itself – not for humans, but computers. And that gave way to the Resource Description Framework (RDF) proposed in '99, and RDFa a few years later.
JSON-LD initially hit the scene in 2011, as the nerd-baby of Google, Bing, Yahoo!, and Yandex. Rather than tying up all that metadata in the markup itself, JSON-LD allowed it to be neatly extracted to it's own location, making it easier to generate and maintain.
The Growing Benefits of Well-Structured Data
The central purpose behind structured data is to enable machines to better understand, classify, and do something with your content. And as mentioned, rich snippets has largely been the only way that's been done. But it's been a heavy hitter.
Google has a number of case studies on this stuff, and it's impressive. For example, Rakuten recipe pages saw a 2.7x increase in traffic after getting serious about structured data. And Rotten Tomatoes saw a substantial increase in click-through rate for pages with structure data vs. those without. Looking through those case studies, I became pretty sold on the value of earning a rich snippet. And if structured data is my way to get there, I'm in.
But the "search" of the future is already looking more generative and less like showing a list of statistically valuable resources. The whole space is exploding right now, providing tremendous value, but there's also a ton of room for improvement.
Consider tools like Perplexity, arguably one of the best AI-based alternatives to Google we have right now. It's incredible how it's able to curate and lace together sources in an eloquent, digestable way. But it's not perfect. I've personally witnessed output that reads eloquently, but actually contains contradictions or untruths derived from piecing sources together in the wrong way. It seems these tools would benefit from some structure to the data they're processing. Given the fact that fewer than half of all websites use any structured data format, getting even a little serious about it could give you the edge you need now, and undoubtedly in the future.
With all that in mind, despite the industry being aggressively shaken up right now, investing in good structured data for your content still seems like a reasonable bet to make.
Getting Started w/ Structured Data
If you've never spent any brain calories on this concept before, it can be a little daunting getting started. You could dive head-first into schema.org and just start absorbing, but I'm falling asleep just typing that suggestion. There are over 800 types and countless combinations of properties you could apply to them – overwhelming. Instead, I'd take the following steps:
First, check if it's already being generated for you. Some platforms will automatically embed JSON-LD based on the type of content they assume you're writing. The Yoast WordPress plugin, for example, is pretty good about it, and it's already found on a ton of WordPress installations (you might not even realize it's there). If that's true, be sure to verify it's valid. It's easy enough to crack open the source code and look for that application/ld+json script tag to do this, but you should also lean on the Schema Markup Validator. If good structured data exists, it'll be listed on the page after the analysis is complete, and you can move on with your life.
If it's not already being done, spend a bit of time looking for a reputable plugin or extension. I mentioned Yoast, but if you're on another platform, there might be a trustworthy plugin for you to vet and adopt. Here's one I found for Statamic that looks solid, but it'll obviously depend on how your content's being managed, which will also determine how involved it'll require you be in setting in up.
The one word of warning here is that you should be aware of the types of structured data they generate for you. Not everything's an article or website. What you don't want is for a plugin to make unreasonably wide assumptions about the content you're writing, and then structure it sub-optimally.
If no other option's on the table, you'll need to get your hands dirty and become familiar with the types and hierarchies yourself. The go-to place for all of these is schema.org, which even has a decent resource on exploring the more common types. But other great options exist as well, such as json-ld.org's playground.
Once you're ready to start crafting JSON, the aforementioned validator will become a very good, helpful friend. And if you've shipped invalid structured data, Google's Search Console will help to cover your butt too. To give you a peak, here's what I recently found in the console for my personal site:
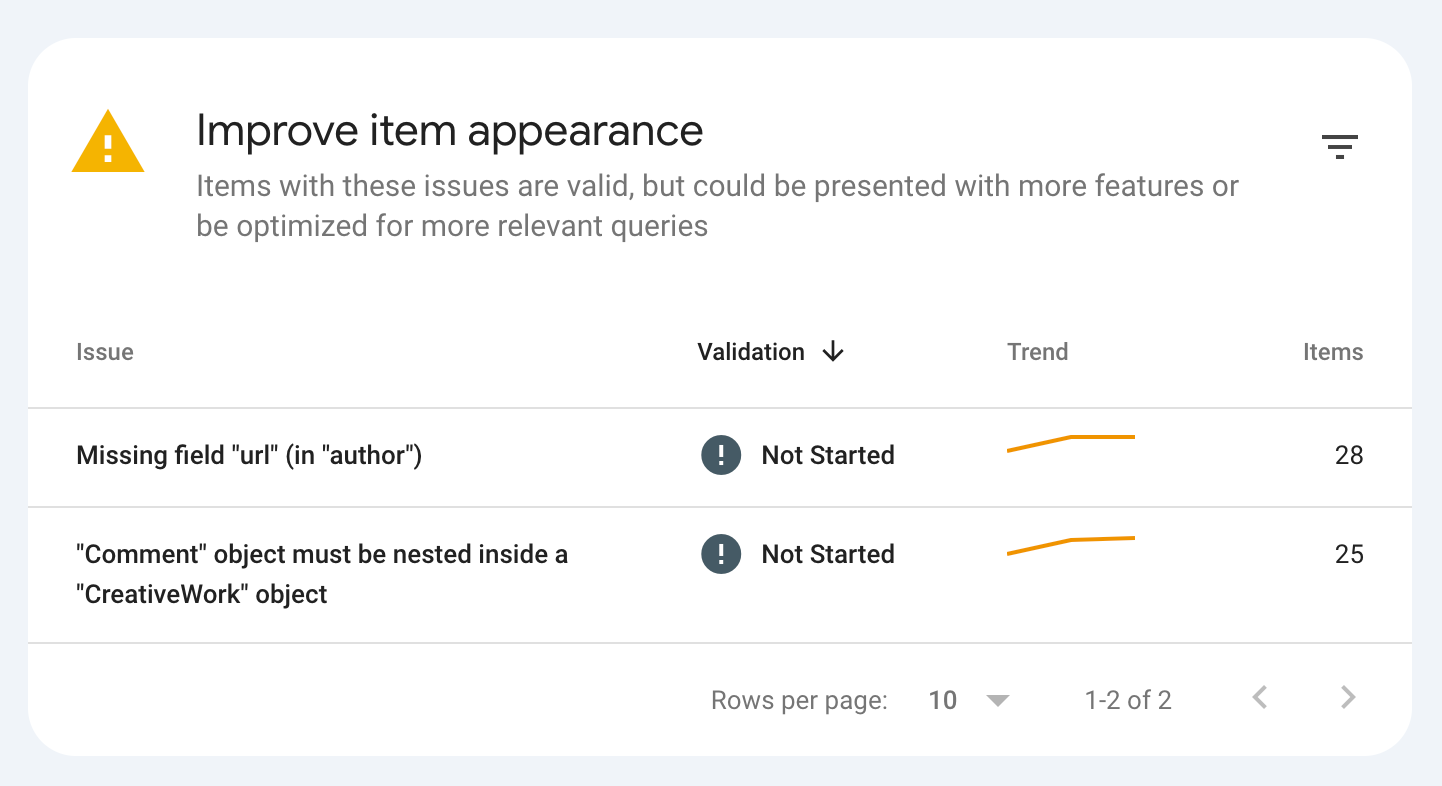
Before I even saw that, I was met with an email warning me about the issues – something I very much appreciated. It's fixed now, by the way.
Assume There's a Type for Everything
When I first started exploring structured data, the types I would reach for were pretty limited – basically "WebPage" or "BlogPosting." But the breadth of types and subtypes is massive, and could be used to classify just about anything. You can even classify any sort of government permit with the GovernmentPermit type:
{
"@context": "https://schema.org",
"@type": "GovernmentPermit",
"issuedBy": {
"@type": "GovernmentOrganization",
"name": "'Murica"
},
"issuedThrough": {
"@type": "GovernmentService",
"name": "The Constitution"
},
"name": "Freedom",
"validFor": "'til Christ returns",
"validIn": {
"@type": "AdministrativeArea",
"name": "every square inch of this blessed land"
}
}Blog post comments are also a great example. I never bothered to build JSON-LD for comments because it never crossed my mind that search engines might be interested in categorizing them. But then, Matt from Testfully.io reached out and let me know of the "Comment" type that'd fit this type of content perfectly. It can be nested within a CreativeWork (like a blog post), which helps to build really clear context around all of the content on a page. Even the user-generated stuff. Since discovering that, it's now auto-generated for every comment rendered by JamComments.
The lesson here is to assume that your subject has a type, and only start looking more broadly if it doesn't. It'll hopefully leave your content structured in a more specific, useful way before one of the bots encounters it.
Leave No Room for Ambiguity
I've grown a strong appreciation for the many facets of technical SEO in recent years, and how every one of those facets ladders up to making clear to search engines that your content deserves being shown to a user over someone else's. As a creator, you can't control which sources search engines choose to prioritize in the list of results, but you can do all you can to make that decision as clear as humanly and technically possible, with no room for ambiguity.
In my opinion, that's a pretty useful question to ask yourself whenever crafting content: "How can I remove every byte of ambiguity when a search engine's sizing up my content?" That's very different from writing for search engines, by the way. Write for a human. Leave vivid clues for the machines.